[1] 서비스 디스커버리
MSA와 같은 분산 환경에서는 Network를 통한 API 호출이 필수적으로 요구된다.
- 다른 서비스를 호출하기 위해서는 위치 정보를 알아야 함 ( IP, Port, URI )
- 전통적 환경 서버들은 위치 정보가 정적인 경우가 많아서 원격 서버의 위치 정보를 설정 파일 등으로 관리가 가능했음
| 전통적 방식 | |
| - 일반적인 환경 - | - 여러 인스턴스 앞 단의 nginx 등의 reverse proxy를 둠 - reverse proxy가 여러 설정 정보를 가지고 있음 |
 |
 |
서비스 디스커버리
- Cloud 기반의 MSA 환경에서는 모든 것이 변화함
- 예로, 사용하던 인스턴스가 죽고 새로운 ip의 인스턴스로 생성 대체되거나, 전략적으로 인스턴스를 추가하는 경우
- 정적인 설정 정보로는 비효율적임
- 인스턴스 갯수, 인스턴스 IP 주소 등이 항상 변화
- Scale out , Fail over , upgrade
- 따라서, 클라이언트는 변화하는 원격 서버의 주소를 알아낼 방안이 필요함
서비스 디스커버리의 중요성
- 새로운 인스턴스들이 언제든 추가되거나 제거됨
- 물리적 위치를 정적으로 저장하고 있는 방식은 비효율적임
- 인스턴스 물리적 주소가 고정되지 않고, 개수 조차 일정하지 않음
- 서비스의 물리적 위치를 몰라도 호출할 수 있어야 함
- 논리적 이름 만으로 호출 가능하고, 인스턴스들의 추가/삭제가 클라이언트에 영향을 끼쳐서는 안됨
서비스 디스커버리의 종류
| Client-Side Service Discovery | - 원격 자원을 호출하는 client가 주소를 조회함 - client에서 어떤 인스턴스를 호출할지 결정함 |
| Server-Side Service Discovery | - Discovery를 담당하는 server가 존재함 - client는 해당 server만 호출 |
1. Client-Side 서비스 디스커버리
 |
 |
- Client가 원격 자원의 주소 정보를 조회하고 유지함 , Service Registry로 부터 서비스들의 주소 정보를 조회함
- Client가 원격 자원들의 주소 정보 기반으로 로드벨런싱 수행 ( 클라이언트 자체 로드 벨런싱 알고리즘 코드를 보유함 )
- 각 인스턴스들은 자신들의 상태를 알리기 위해 Heartbeat를 Service Registry에 전달함
- client가 인스턴스에 문제가 생기게 되면 Service Registry에게 이를 알려주고 location list가 수정되고, 인스턴스가 교체됨
- Service Registry가 장애 발생 시 Location List는 클라이언트의 캐쉬에 저장되므로 일정 기간 사용이 가능하다.
장점
- Service Registry를 제외하고는 다른 추가 컴포넌트가 불필요함
- LB 등의 관리가 필요없이 클라이언트에 책임을 맡기고 클라이언트는 다양한 로직을 추가하는 것이 가능
단점
- client 언어와 framework 별로 LB 로직 개발이 필수적임
- LB 및 장애 내성에 대한 책임이 모두 client에 존재함
- 조직 통합적 관리가 어려움
2. Server-Side 서비스 디스커버리

- Client는 원격 서비스 인스턴스에 대한 정보 유지를 하지 않음
- client는 Load Balancer를 통해 원격 서비스를 호출함 ( LB는 인스턴스 목록을 service registry로 부터 조회함 )
장점
- 클라이언트가 LB 등 추가적인 개발이 불필요함
- 원격 서비스 호출에 대한 모든 기능이 LB로 추상화됨
- 쿠버네티스에 기본적으로 Server-side 서비스 디스커버리 기능이 존재함
단점
- 서버 측, 서비스 디스커버리 기능이 있는 LB를 별도로 설치하고 관리해야함
Service Registry
- 서비스 정보를 등록하고 서비스 정보를 조회 가능한 Database
- 외부에 서비스 등록 API와 서비스 조회 API 노출 필요
- 항상 최신 정보를 유지해야 함
- 고가용성을 만족 해야 함
- 서비스 인스턴스로부터 주기적으로 HeartBeat을 확인
- 문제 있는 인스턴스는 목록에서 제거
- Client 입장에서는 Eventual Consistence를 고려해야 함
- 장애 발생한 인스턴스 정보를 실시간 갱신하는 것은 어려움 ( Hearbeat 주기 관련 )
Service Registry의 고가용성 보장

- Service Registry를 Active/Active 구조로 유지함
- Service Registry간 정보를 공유함
- Client에서 원격 서버 정보를 Cashing 하는 전략
- Service Registry 장애 발생 시 원격 자원 호출이 가능하고 부하가 감소함
Service Discovery 패턴 적용 방법
Spring Cloud Netflix Eureka
- Netflixt Eureka로 부터 파생된 프로젝트로 대규모 분산 환경의 서비스 디스커버리 지원
- Eureka server , Eureka Client로 구성 됨
- 서비스들이 Eureka CLient가 되며 실행 시점에 Eureka Server에 자기 자신의 정보를 등록함
Spring Cloud Netflix Eureka의 기능
- 서비스 등록 : 새로운 서비스들이 자신의 정보를 등록함
- 클라이언트의 서비스 탐색 : 클라이언트가 서비스들의 물리적인 주소를 질의함
- 정보 공유 : 서비스 디스커버리 노드들 간에 정보를 공유함

서비스가 생성되면 자신의 정보를 에이전트에 등록
클라이언트는 에이전트를 이용하여 서비스 위치를 검색 가능함
에이전트들은 클러스터링 가능하며, 각자의 정보를 다른 노드들에 공유
모든 서비스의 인스턴스는 에이전트에게 상태정보를 전송
Eureka의 특징
- 고가용성 : 서비스의 정보를 여러 개 노드가 공유하고 동시에 동작하는 Active/Active 구조로 고가용성 만족
- 피어 투 피어 구조 : 서비스 디스커버리 클러스터의 모든 노드들이 서비스 상태를 공유함
- 장애 내성 : 에이전트는 인스턴스의 비정상 상태를 감지하고 제거함 ( 사람 개입 필요 X )
- 회복성 : 클라이언트는 서비스 정보를 로컬에 캐시함 (Ribbon) , 이를 통해 가용하지 않을 때 로컬 캐시 정보로 접근 가능
- 부하 분산 : 클라이언트의 요청을 후방 서비스들에게 분산하고 전달함
Eureka와 Ribbon

- 서비스 호출 시 마다 정보를 질의하는 방식은 비효율적임
- Ribbon은 에이전트로부터 받은 정보를 로컬에 캐싱
- 캐싱 한 정보로 서비스를 호출
- 주기적으로 에이전트에 다시 질의하여 캐시 정보를 갱신
- Ribbon은 Client-Side LB 기능도 수행함
- Service Registry로 부터 받은 서비스 인스턴스 목록을 기반으로 LB를 수행함 ( defalut : Round Robin )
| (정리) - MSA는 다양한 서비스/인스턴스 호출의 협업이 필수적이고 원격 서버의 주소를 정적으로 저장하는 것은 비효율적임 - Service Registry를 통해 원격 서버의 주소 정보를 동적으로 사용 가능함 - Spring Cloud Netflix Eurek의 유레카 클라이언트 유레카 서버로 Service Discovery 구현이 가능함 |
[2] 설정 외부화 패턴의 이해
설정 정보 ? SW 개발 시 설정 정보는 반드시 필요한 사항으로 엔터프라이즈 급은 수백 개 이상의 설정 정보가 존재함
( DB 서버나 외부 자원 인증 정보, 캐시 정책, 외부 라이브러리 설정, 로그 레벨 .... )
- 설정 정보는 고정되지 않고 항상 유지 보수나 개발하면서 변경 된다.
- 설정 정보가 문제가 발생하면 , Application이 가동 되는 도중이나 Runtime에 비정상 동작, 중단될 가능성 있음
- 즉 설정 정보 관리는 Application Code 와 마찬가지로 중요함
- 기존 설정 정보 관리는 아래와 같음
- 소스코드 상 상수로 관리
- Json, Properties 등의 파일로 관리
- OS 환경 변수로 관리함
기존 설정 정보 관리의 문제점
- 100개의 인스턴스에 대해 서비스 설정 변경
- 기존 방법은 설정 수정 후 빌드 및 100개 인스턴스에 배포해야 함
- 특정 시점 신/구 설정이 공존하고 특정 인스턴스에 배포/OS 환경 설정 변경 누락 가능성이 존재함
- 결과적으로 MSA Scale-out의 장애물로 작용함
- 환경별 빌드를 매번 새로 해야함
- 빌드 시점에 어떤 환경 변수 파일을 이용할 것인지 결정
- 단일 Build Artifact로 모든 환경에 배포를 하는 것이 Best Practice
MSA에서의 설정 관리
- MSA내에는 다수의 서비스, 다수의 환경, 다수의 인스턴스가 존재함
- 모든 인스턴스/서비스는 사람의 개입을 최소화 하면서 신속하게 시작되어야 한다.
설정의 외부화 : 설정 관리 문제에 대한 해결책
- 설정 정보를 배포되는 코드에서 완전히 분리
- 중앙 저장소에 설정 정보 저장
- 서버 시작 시, 중앙 저장소에서 설정 정보 Fetch
- 설정 변경 시 재빌드/배포 없이 모든 인스턴스가 실시간 반영 가능
설정 외부화 패턴
- 설정 정보를 중앙 저장소에 존재하게 함
- 인스턴스 시작 시 중앙 저장소에서 설정 정보를 읽음
- 설정이 변경 되면 서비스에서 설정 데이터를 갱신
- 설정 정보 형상관리 도구를 이용해 다수 Review후 변경 함 ( Git .. )
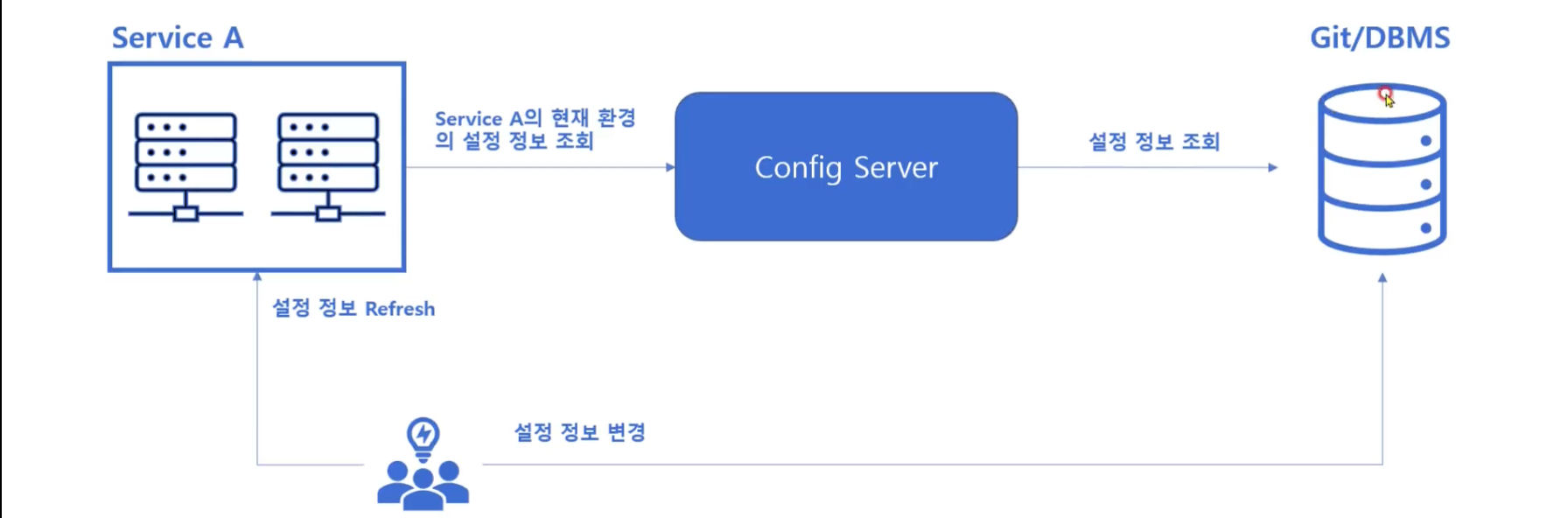
설정 외부화를 위한 기술
- Spring Cloud Config
- KuberNetes ConfigMap
- Consul
- Zookeeper ..
Spring Cloud Config

- Spring Project에 활용해 설치 및 설정이 용이하고 , Spring Boot App과 용이한 통합이 가능함
- Git과 통합도 가능함
- Clinet/Server 구조로 이루어짐 ( Service 인스턴스들이 모두 Config Client가 됨)
- Config Server는 신규 Spring Boot 기반 Application을 생성하여 배포해야 함
- Maven 설정, annotation 설정 , yaml 설정이 필요함 ( 소스코드 개발은 필요 X )

(정리)
- 설정 정보는 MSA에서 중요한 이슈 중 하나
- 설정 외부화 : 설정 정보를 Source code에서 완전 부리하고 외부 서버에 저장하는 것
- 각 application이 가동되는 시점에 Config serer로 부터 외부 설정 정보를 Fetch 함
- 설정 외부화를 사용하면 MSA scale-out 장애물을 제거 가능
[3] 회로 차단기 패턴 & 클라이언트 회복성 패턴
분산 시스템의 장애는 자주 발생하고 이를 대응하는 시스템을 구축하는 것은 중요한 일이고, 이를 위해 시스템의 중복성을 더하는 방식으로 장애에 대응할 준비를 함
- 핵심 서버 클러스터링
- 인프라를 여러 곳에 분산
- 기존 방식은 개별 시스템이 완전히 실패하는 경우에는 적절해 보임
- 동기식 호출 기반 MSA 환경은 일부 서비스의 성능 저하가 전체 시스템의 장애로 이루어지는 경우가 존재함
- 전체가 아닌 특정 서비스의 성능 저하를 감지해 빠르게 대응하는 것이 중요함
[Example]

특정 API 트랜잭션에 대해 10개의 서비스가 협업하는 경우( 9개 서비스는 정상 , 1개 서비스만 성능이 느림 )
(1) ==> 성능이 느린 서비스의 응답 시간은 점점 느려지고, 호출하는 client 자원도 고갈됨 ( 스레드 풀 등 ) )
(2) 서비스의 성능저하는 시간이 지날수록 전체 시스템에 전파됨 ==> 전체 시스템 다운
클라이언트 회복성 패턴
- 원격 서비스의 비정상 동작에 대해 클라이언트르 보호함
- 사람이 개입해 클라이언트를 보호하는 게 아닌 호출하는 주체가 본인을 보호하는 패턴
- 원격 자원의 성능 저하가 시스템 전체로 전파되지 않게 함 => ( 빠른 실패 , 실패의 격리 )
1. 클라이언트 회복성 패턴 : Client-Side Load Balancing
• 클라이언트가 인스턴스 목록을 기반으로 부하를 분산하고 문제 감지 시 호출 목록에서 제거함
• Ribbon이 역할을 수행함 Eureka로부터 인스턴스 목록 조회
• 인스턴스 목록에 기반하여 Load Balancing 수행
• 인스턴스에 주기적으로 Ping 전송 후 Health check
• 비정상 인스턴스를 Load Balancing 대상에서 제외
=> 인스턴스 레벨로 문제를 인식
2. 클라이언트 회복성 패턴 : Circuit Breaker Pattern

• 전기회로 차단기의 개념을 차용한 패턴
• 전기 시스템에서 과전류 발생 시 회로를 차단하고 과전류에 손상되지 않도록 보호
• SW 회로차단기는 원격 서비스의 호출을 모니터링
• 특정 원격 자원에 대한 호출이 정해진 만큼 실패할 경우 해당 원격 자원을 반복적으로 호출하지 않도록 차단
• 문제되었던 서비스가 복원되고 다시 정상 인식하고 호출을 자동으로 하는 기능을 포함함
=> 서비스 레벨로 문제를 인식
3. 클라이언트 회복성 패턴 : Fallback pattern
• Circuit 차단 시 예외 발생 대신 대체 행동을 정의함
• 다른 데이터베이스를 호출하거나, 향후 처리를 위해 Retry queue에 넣거나, 하드코딩 된 결과를 응답
예) 개인화 추천 서비스가 다운되면 인기추천 목록을 조회하여 응답
4. 클라이언트 회복성 패턴 : Bulkhead Pattern
• 선박 건조 시 선체 일부에 구멍이 뚫려도 다른 부분에 영향이 없도록 각 구역을 완전하게 격리하는 아이디어 차용
• 원격 자원에 대한 호출을 자원 별 스레드 풀로 격리하여 관리 ( 문제가 발생한 스레드 풀만 다운되고, 격리됨 )
• 특정 자원의 성능 저하가 다른 자원의 스레드 풀에 영향 주지 않음
클라이언트 회복성 패턴의 핵심
| 빠른 실패 (fail fast) | - 실패를 최대한 빨리 인지하고 시스템 전체 영향이 가지 않도록 방지 - 부분적인 장애가 완전한 장애보다 나음 |
| 원만한 실패 (fail gracefully) | - fallback을 이요해 원격 호출 실패 시, 대체 경로를 사용해 시스템이 작동하도록 함 |
| 원만한 회복 (recover seamlessly) | - 실패한 자원이 정상화 되면 사람 개입없이 해당 자원에 대한 차단 해제 후 접근 허용 - 수 백, 수 천개 대규모 클라우드 기반 시스템에서는 원활한 회복이 매우 중요 |
회로차단기 패턴 적용 : Hystrix
Hystrix 주요 기능
• Circuit Breaker
- 원격 호출에 대한 특정 단위 별로 Circuit Breaker 생성 됨
- 호출에 대한 모든통계
• Fallback
- Exception 발생 시 대체 코드 정의
• Thread Isolation
- 실제 호출을 새로운 thread가 intercept하여 대신 호출
- Hystrix에 의해서 관리되는 Thread
• Timeout
- 동일한 정책의 Timeout 적용 가능, Hystrix에 의해 관리됨
- Socket, Connection, Read, JDBC Socket, JDBC Query timeout ...
• 대시보드 지원
- 서킷 브레이커가 수백 개 생길 수 있으므로 이를 분석하고 관리할 대시보드가 필요함
Hystrix 시나리오

=> 서비스 C에 문제가 생기면 , 서비스 B도 영향을 받고 서비스 A도 영향을 받아 결국 전체 시스템 장애를 야기함

1. Hystrix 는 서비스 C로의 실패 회수를 추적
2. 일정 수준이상으로 실패하면 Circuit Open
3. 서비스 B는 예외를 발생시키거나 대체 코드를 실행
4. 서비스 C에 호출이 유입되지 않아 복구 가능한 시간이 생김
5. 회로 차단기는 서비스 C를 주기적으로 호출하고 성공하면 Circuit Close
[ Default : 10초 간격 호출 집계 , 1초 이상 호출이 50%를 차지하면 회로를 차단 (커스텀 가능) ]
(정리)
- 클라이언트 회복성 패턴은 장애 발생한 원격 자원으로부터 클라이언트가 자신을 보호하는 패턴
- 회로 차단기 패턴은 클라이언트 회복성 패턴의 일종으로 원격 서비스가 장애라고 판단 시 호출을 차단함
- 장애를 빠르게 판단하고 격리한는 것이 회로 차단기의 목표
[3] API GateWay
: 시스템 내부의 모든 서비스에 대한 API 호출의 Gate를 담당함
- 특정 서비스에 대한 API 호출이 실제 서비스에 도달 하기 전/후 다양한 기능 수행 ( 라우팅, 인증, 로깅 등 .. )
- 라우팅은 NGINX등 웹서버를 사용 가능하지만, 공통 로직은 불가능
- Netflx Zuul, Spring cloud gateway, Amazone API Gateway ..
문제점
- MSA 환경에서는 서비스마다 언어/프레임워크가 상이함
- Cross Cutting Concerns
- 각 서비스마다 동일하게 적용해야 하는 기능들의 집합 ( 인증/인가, 로깅, 분산 추적 .. )
- 각 서비스마다 별로로 각자 개발하는 것은 비효율적임 ( 100% 동일한 동작 보장이 어려움 )
- 공통 라이브러리를 만들어서 사용하는 방법이 있음
- 라이브러리에 대한 서비스들이 의존함 -> high coupling
- 공통 코드가 개발되어 있는 자체 프레임워크 도입하는 방법도 있음
- 서비스 별로 사용 언어가 다르면 어려움
MSA Cross Cutting Concerns
: Cross Cutting Concerns를 서비스들과 독립적으로 구성함
( 단일적인 정책 지점을 만들어 모든 호출이 해당 지점을 통한 후 각 서비스로 라우팅 되도록 구성함 )

(정리)
- MSA 환경에 대해 모든 API에 대해 공통적으로 처리해야 하는 기능 필요
- 서비스 별로 기술이 상이할 수 있어 서비스별 개발이 어려움
- 독립적인 API Gateway로 공통 기능 및 라우팅 기능 개발
- Spring cloud netflix zuul을 사용해 기존 spring cloud 프로젝트와 통합 된 Api gateway 개발 가능
'Infra > MSA' 카테고리의 다른 글
| [MQTT]Message Queueing Telemetry Transport (0) | 2024.05.31 |
|---|---|
| MSA를 위한 기술들 (0) | 2022.05.28 |
| MSA를 위한 기술 (0) | 2022.05.26 |
| MSA 분리 전략 : 도메인 주도 설계 (0) | 2022.05.01 |
| MSA 도입을 위한 역량 및 필요조건 (0) | 2022.04.15 |
