Data Mining
: 대규모 데이터셋에서 패턴, 규칙, 트랜드 등의 유용한 정보를 추출하기 위해 사용되는 과정
- 지식을 추출하기 위해 데이터는 저장, 관리, 그리고 분석이 수행되어야 함 → 데이터 마이닝의 필요성
- 데이터 마이닝 ≈ 예측 분석 ≈ 데이터 과학 ≈ 머신 러닝 ≈ 데이터 중심 AI
- 매우 큰 데이터셋에서 의미 있는 정보를 추출하는 것이 어렵기 때문에 현재 관심받는 연구 분야
- 주로 확장가능한 알고리즘에 중점을 두는데, 이 때 병렬처리가 필수적으로 요구됨
| Descriptive methods | ▪ 데이터를 설명하는 사람이 해석할 수 있는 패턴 찾기 ▪ 예: 클러스터링 |
| Predictive methods | ▪ 일부 변수를 사용하여 다른 변수의 알려지지 않은 값 또는 미래 값 예측 ▪ 예: 추천 시스템 |

데이터 마이닝은 데이터베이스, 기계 학습, 컴퓨터 과학 이론과 같은 여러 분야와 겹치며, 이들 각각의 분야에서 데이터 마이닝을 바라보는 관점이 다르며 각 관점의 특징은 아래와 같다.
| 데이터베이스 관점 | 데이터 마이닝을 대규모 데이터를 분석하는 극단적 형태의 질의 처리로 봄. 결과는 질의의 답변 |
| 기계 학습 관점 | 데이터 마이닝을 모델의 추론으로 간주함. 이 경우 결과는 모델의 파라미터이다. |
| 컴퓨터 과학 이론 | (랜덤화된) 알고리즘에 초점을 맞추며, 데이터 마이닝은 이 알고리즘을 사용하여 의미 있는 정보를 추출하는 과정으로 봄 |
보노페로니 원칙
데이터 마이닝에서는 "의미 없는 패턴 발견"의 위험이 있습니다. 이는 통계학에서 보노페로니 원칙으로 알려져 있습니다. 이것은 사용 가능한 데이터 양보다 더 많은 곳에서 흥미로운 패턴을 찾으려고 하면 결국에는 쓸모없는 결과를 찾을 수 있다는 원칙입니다.
따라서 데이터 분석 과정에서는 실제로 의미 있는 발견과 우연히 나타난 패턴을 구별하는 것이 중요합니다.
빅데이터
빅데이터는 기존 데이터 관리 도구로는 처리하기 어려운 대규모의 데이터를 다루는 기술과 방법론을 의미합니다.
빅데이터의 주요 특징으로는 3V, 5V 가 있음.
주요 과정은 ( 수집 → 저장/로딩 → 처리/탐색 → 분석/어플리케이션 ) 으로 이루어진다.
| 3V | |
| Volumn (양) | 빅데이터는 대규모의 데이터 양을 다룹니다. 이는 테라바이트(TB)부터 페타바이트(PB) 이상의 규모일 수 있습니다. Variety (다양성): 빅데이터는 다양한 종류의 데이터를 포함합니다. |
| Variety (다양성) | 빅데이터는 다양한 종류의 데이터를 포함합니다. 구조화된 데이터부터 비구조화된 데이터, 텍스트, 이미지, 비디오 등 다양한 형태의 데이터가 있습니다. |
| Velocity (속도) | 빅데이터는 빠른 속도로 생성되고 수집됩니다. 이는 실시간 데이터 스트림이나 대규모 트랜잭션 데이터와 같이 발생할 수 있습니다. |
| 5V | |
| Veracity (정확성) | 데이터의 신뢰성과 정확성을 의미합니다. 빅데이터에서는 데이터의 진실성과 신뢰성을 보장하는 것이 중요합니다. |
| Visaulization (시각화) | 데이터를 시각적으로 표현하여 이해하기 쉽게 합니다. 시각화는 데이터 분석 및 의사 소통을 용이하게 합니다. |
빅 데이터의 어플리케이션 구조

일반적인 빅데이터 처리과정
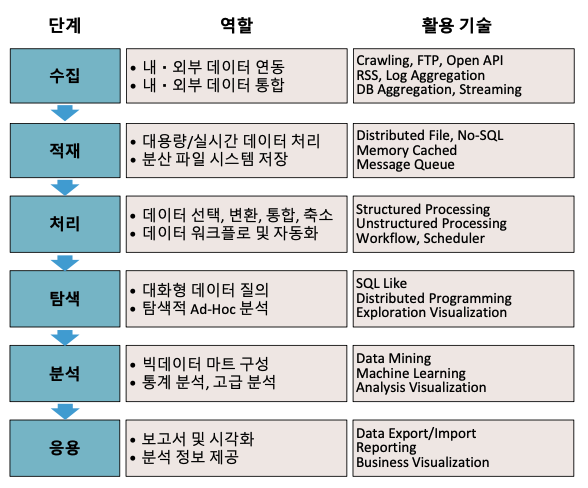
빅 데이터 수집 절차 및 보안과 관련된 기술적 요소
| 수집 ( Collectiong ) | Crawling, OpenAPI, Streaming, DB Aggregation |
| 저장 및 로딩 ( Storing Loading ) | HDFS, NoSQL, Memory cached, Message Queue |
| 처리 및 탐색 ( Processing Exploring ) | Structured Processing, Unstructured processing, Scheduler |
| 분석 애플리케이션 ( Analysis Application ) | Data Mining, ML, Data Export, Reporting |
빅데이터 보안 (Big Data Security)
• Access Control Security : 데이터 접근 제어를 위한 정책 정의
• Apache Knox : 하둡 클러스터를 위한 보안 프레임 우커로, 인증 . 및접근의 단일 지점 역할 ( LDAP, KDC )
• Apache Sentry : 하둡에 저장된 데이터에 대해 세밀한 역할 기반 접근 제어 ( SA : Sentry Agent )
• Apache Ranger : 하둡에 대한 포괄적인 보안 관리 프레임워크를 제공하며, 접근 제어, 감사 . 및사용자 관리를 하둡 구성 요소 전반에 걸쳐 지원함
• Kerboros : 하둡 환경 내 노드 간 인증되고 암호화된 통신을 보장하기 위한 네트워크 인증 프로토콜 ( AS, TGS )
MapReduce
: 대규모 데이터를 처리하기 위한 프로그래밍 모델과 프레임워크로, 빅데이터와 데이터 마이닝 분야에서 널리 사용된다. mapReduce를 통해 대용량 데이터를 분산환경에서 효율적으로 처리하고, 데이터 마이닝 알고리즘을 적용하여 유용한 정보를 추출할 수 있다.
MapReduce는 대규모 데이터 처리와 데이터 마이닝을 위한 대규모 컴퓨팅에 중점을 두는 과정에서 중요한 역할을 한다.
주로 대규모 데이터 처리는 다음과 같은 과제에 직면함
- 계산을 어떻게 분산시켜서 효율적으로 처리할 것인가
- 분산/병렬 프로그래밍을 어떻게 구축할 것인가
구글이 개발한 대용량 데이터 처리를 위한 계산 및 데이터 조작 모델(Cluster Architeture) 은 MapReduce 기술을 통해 위의 문제에 대한 해결책을 제공
| 데이터 이동 및 복사간의 Cost 비용 발생 | [1] 데이터를 복사하는 대신 연산을 데이터 근처로 가져옴 [2] 데이터의 신뢰성을 위해 파일을 여러 번 저장 |
| [1] 데이터를 복사하는 대신 연산을 데이터 근처로 가져옴 : 맵 리듀스로 해결 [2] 데이터의 신뢰성을 위해 파일을 여러 번 저장 : 분산 파일 시스템 |
|
분산 파일 시스템:
청크 서버
- 파일을 연속적인 청크로 분할 ( 일반적으로 각 청크는 16-64MB )
- 각 청크는 복제됨 (보통 2배 또는 3배)
- 복제본을 다른 랙에 유지
마스터 노드 (네임 노드)
- 파일 저장 위치에 대한 메타데이터 저장 복제될 수 있음
파일 액세스용 클라이언트 라이브러리
- 청크 서버를 찾기 위해 마스터에게 연락
- 데이터에 직접 액세스하기 위해 청크 서버에 연결
분산 파일 시스템은 데이터를 여러 기계에 걸쳐 "청크" 형태로 저장하는 신뢰성 있는 시스템입니다. 각 청크는 다른 기계에 복제되어, 디스크나 기계 오류로부터의 원활한 복구를 가능하게 합니다. 이 구조는 데이터를 저장 위치에서 직접 계산함으로써, 데이터 이동에 소모되는 시간과 자원을 줄여줍니다. 청크 서버는 데이터 저장 뿐만 아니라 계산 서버로도 활용되어, 데이터 처리 중 네트워크 병목 현상을 줄이고 전체 시스템 성능을 향상시킵니다.
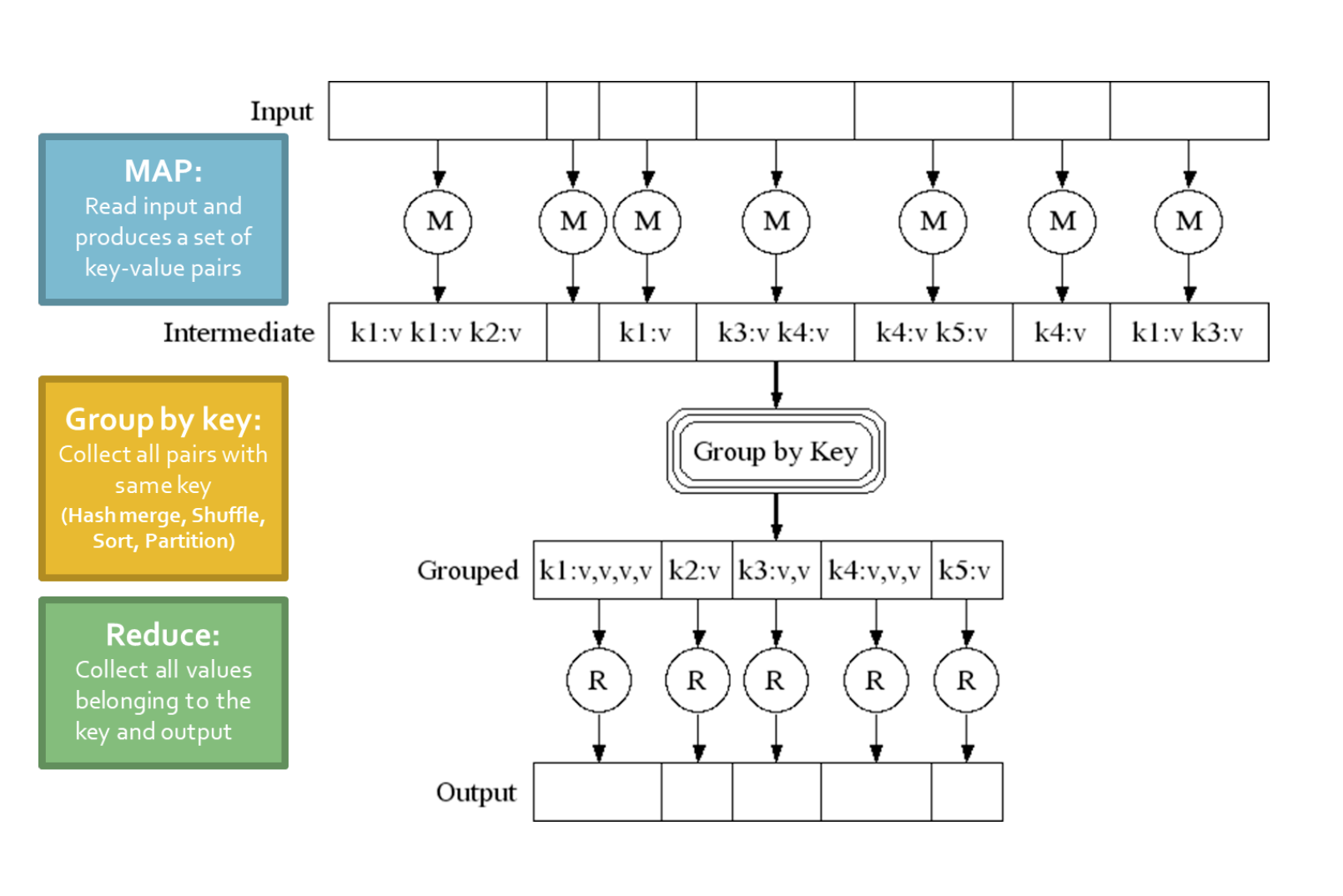
MapReduce의 기본 개념은 크게 두 단계로 나누어짐
[1] Map 단계:
- 입력 데이터를 키-값 쌍으로 매핑함
- 분산된 환경에서 동시에 처리할 수 있도록 데이터를 조각으로 나눕니다. ( chuck 단위)
[2] Reduce 단계:
- Map 단계에서 출력된 중간 키-값 쌍들을 키별로 그룹화함
- 각 키에 대한 값들을 병합하여 최종 결과를 생성.
MapReduce 모델은 분산 및 병렬 프로그래밍의 복잡성을 추상화하며, 개발자가 대규모 데이터 세트에 대한 복잡한 계산을 쉽게 구현할 수 있도록 합니다. 이로 인해, 데이터 마이닝과 같은 대규모 데이터 처리 작업이 훨씬 쉬워집니다.
 |
 |
| Single Node Architecture | Cluster Architecture |
MapReduce의 필요성
대규모 컴퓨팅
상용 하드웨어의 데이터 마이닝 문제에 대한 대규모 컴퓨팅의 도전 과제
- 계산을 어떻게 분산시킬 것인지에 대한 결정
- 분산 프로그래밍을 쉽게 작성할 수 있는 방법론
- 기계 고장: 예를 들어, 한 서버는 3년(1,000일) 동안 작동할 수 있지만, 1,000대의 서버가 있다면 매일 1대의 서버가 고장날 것으로 예상. ( 2011년에 구글이 약 100만 대의 기계를 가지고 있었다고 추정되면, 매일 1,000대의 기계가 고장! )
Programming Model : MapReduce
MapReduce 특징
1. 쉬운 병렬 프로그래밍
2. 보이지 않는 하드웨어 및 소프트웨어 장애 관리
3. 매우 큰 규모의 데이터를 쉽게 관리할 수 있습니다
[ Hadoop, Spark(이 클래스에 사용됨), Flink 및 "MapReduce"라는 원래 Google 구현을 포함한 여러 구현이 있음 ]
MapReduce 단계별 절차
MapReduce는 대규모 데이터셋을 처리하기 위한 프로그래밍 모델로, 입력 데이터를 처리하여 결과를 도출하는 과정을 'Map'과 'Reduce' 두 단계로 나눈다. [ 대용량 데이터를 효율적으로 처리할 수 있도록 설계 ]
(1) Map 단계:
- 사용자가 작성한 Map 함수를 각 입력 요소에 적용합니다.
- Mapper는 단일 요소에 Map 함수를 적용하고, 여러 Mapper가 Map 작업(병렬 처리의 단위)에서 그룹화됩니다.
- Map 함수의 출력은 0개, 1개 또는 그 이상의 키-값 쌍 집합입니다.
(2) Group by key 단계 (정렬 및 셔플):
- 시스템은 모든 키-값 쌍을 키별로 정렬하고, 키-(값 리스트) 쌍을 출력합니다.
(3) Reduce 단계:
- 사용자가 작성한 Reduce 함수가 각 키-(값 리스트)에 적용됩니다.
- 구조는 동일하게 유지되지만, Map과 Reduce는 문제에 맞게 변경됩니다.

MapReduce 패턴은 복잡한 데이터 처리 작업을 간단하고 효율적으로 해결할 수 있도록 도와주며, 특히 대규모 분산 시스템에서 강력한 성능을 발휘함. 모델을 통해 개발자는 데이터 처리 로직에 집중할 수 있으며, 데이터 분산, 병렬 처리, 오류 처리 등의 복잡한 작업은 MapReduce 프레임워크가 자동으로 처리함
맵 리듀스 작업의 예
1. 거대한 텍스트 문서를 가지고 있습니다 -> 각 구별된 단어가 파일에 나타나는 횟수 수 (워드 카운팅)

그 밖의 예시
- 웹 서버 로그를 분석하여 인기 있는 URL 찾기
- 통계적 기계 번역:
- 45단어 시퀀스가 큰 문서 말뭉치에서 발생할 때마다 횟수를 카운트해야 합니다
 |
 |
 |
| Word count using MapReduce | Map-Reudce : A Diagram | Map-Reudce : In Parallel |
MapReduce 환경은 다음과 같은 작업을 관리합니다:
- 입력 데이터 분할: MapReduce는 큰 데이터 세트를 작은 청크로 나누어 여러 머신에서 병렬로 처리할 수 있도록 합니다.
- 프로그램 실행 스케줄링: 분할된 데이터를 처리하기 위해 여러 머신에 걸쳐 프로그램의 실행을 스케줄링합니다.
- 키별 그룹화 단계 수행: 모든 키-값 쌍을 키에 따라 정렬하고 그룹화하는 단계입니다. 실제로 이 단계는 병목 현상이 발생하기 쉬운 부분입니다.
- 실패 처리: 분산 노드에서 실패하더라도 처리 과정이 중단되지 않도록 관리합니다.
- 노드 간 통신 관리: 작업 분배와 결과 수집을 위한 머신 간 통신을 관리합니다.
실패 처리 방법:
- Map 작업자 실패: 실패한 작업자에게 할당되었던 Map 작업이 완료되었거나 진행 중이었던 작업은 대기 상태로 재설정되고, 다른 작업자에게 재스케줄링됩니다. Map 작업이 다른 작업자에게 재스케줄링되면 Reduce 작업자들에게 통지됩니다.
- Reduce 작업자 실패: 진행 중인 Reduce 작업만 대기 상태로 재설정되고, 해당 Reduce 작업은 다시 시작됩니다.
이러한 기능을 통해 MapReduce 환경은 대규모 데이터 처리 작업을 안정적으로 처리할 수 있는 강력한 도구가 됩니다. 데이터 분할, 스케줄링, 그룹화, 실패 처리 및 통신 관리 기능은 복잡한 데이터 처리 작업을 단순화하고 자동화하는 데 큰 역할을 합니다.
Map-Reduced
프로그래머의 역할 : Map and Reduc and input files의 workflow 수립
 |
[1] 입력 읽기: - 데이터를 읽어서 키-값 쌍의 집합으로 읽음 [2] Map 변환: - Map 단게에서 입력된 k-v쌍을 새로운 k'v'쌍으로 변환 [3] 정렬 및 셔플: - 변환된 k'v'쌍을 정렬하고 셔플링하여 출력 노드로 보냄 ( 이 과정에서 동일한 키(k')를 가진 모든 k'v'쌍이 같은 reduce작업으로 전송됨 ) [4] Reduce 처리: Redcue 단계에서 키별로 그룹화된 k'v'쌍을 처리하여 새로운 키-값(k''-v'')쌍을 생성 [5] 결과 쓰기 최종적으로 생성된 키-값 쌍을 output으로 작성 |
Data-Flow
- 입력 데이터와 최종 출력 데이터는 분산 파일 시스템(FS)에 저장됩니다.
- 스케줄러는 입력 데이터의 물리적 저장 위치에 "가깝게" 맵 태스크를 스케줄링하려고 합니다.
- 중간 결과(Intermediat results[grop-by-key]는 맵 및 리듀스 작업자의 로컬 파일 시스템에 저장됩니다.
- 출력은 종종 다른 MapReduce 작업의 입력으로 사용됩니다.
마스터 노드 ( 맵 리듀스의 조정자 역할 )
- 마스터 노드는 corr을 담당합니다:
- 태스크 상태: ( idle(유휴 상태), in-progress(작업 중), completed(작업완료) )
- 유휴 태스크는 워커 노드가 사용 가능해지면 스케줄됩니다. [그 동안은 대기]
- 맵 태스크가 완료되면, 그 위치와 각 리듀서에 대한 R개의 중간 파일 크기를 마스터에게 보냅니다.
- 마스터는 이 정보를 리듀서에게 전달합니다.
- 마스터는 주기적으로 워커 노드에게 핑을 보내 실패를 감지합니다.
실패 처리
맵 작업자 [Map worker] 실패:
- 작업자에서 완료되었거나 진행 중인 맵 태스크는 유휴 상태로 재설정됩니다.
- 태스크가 다른 작업자에게 재스케줄될 때 리듀스 작업자에게 알립니다.
리듀스 작업자 [Reduce worker] 실패:
- 진행 중인 태스크만 유휴 상태로 재설정됩니다.
- 리듀스 태스크는 재시작됩니다.
마스터 [Master] 실패:
- MapReduce 작업은 중단되고 클라이언트에게 알립니다.
맵 및 리듀스 작업의 수에 대한 지침
- M 맵 태스크와 R 리듀스 태스크가 있습니다. 이는 맵 태스크(M)와 리듀스 태스크(R)의 수를 나타냅니다.
경험칙으로, M(맵 태스크의 수)은 클러스터 내 노드의 수보다 훨씬 커야 합니다. 이는 데이터 처리 작업을 더욱 효율적으로 분배하기 위함입니다.
- 일반적으로 맵 태스크당 하나의 분산 파일 시스템(DFS) 청크가 사용됩니다. 이는 입력 데이터가 분산 파일 시스템에 저장될 때, 각 맵 태스크가 처리할 데이터의 일부분을 할당받는다는 것을 의미합니다.
- 동적 부하 균형을 개선하고, 작업자(노드)의 실패로부터 복구하는 시간을 줄이기 위해 맵 태스크의 수를 늘립니다. 이는 각 태스크가 처리해야 할 데이터 양이 적어지며, 어떤 노드가 실패하더라도 다른 노드에서 빠르게 해당 태스크를 인수하여 처리할 수 있기 때문입니다.
- 보통 R(리듀스 태스크의 수)은 M(맵 태스크의 수)보다 작습니다. 이는 최종 출력 데이터가 R 개의 파일에 분산되어 저장되기 때문입니다. 리듀스 태스크는 맵 태스크의 출력을 받아 최종 결과를 생성하는 역할을 하며, 각 리듀스 태스크는 최종 결과의 일부분을 담당합니다.
이렇게 맵 태스크와 리듀스 태스크의 수를 조정함으로써, MapReduce 작업은 클러스터의 자원을 효율적으로 활용하고, 데이터 처리 과정에서 발생할 수 있는 다양한 문제들(예: 노드 실패)에 더욱 유연하게 대응할 수 있습니다.
작업 세분화 & 파이프라이닝
세분화된 태스크: MAP 태스크 >> 시스템(노드)
▪ 장애 복구에 소요되는 시간 최소화
▪ 맵 실행으로 파이프라인 셔플링 가능
▪ 동적 로드 밸런싱 향상

Backup Tasks
문제상황 : 느린 워커가 작업 완료 시간을 크게 늘리는 경우가 발생함
- 노드 머신에서 다른 작업이 실행 중인 경우
- 디스크 문제나 기타 발생 가능한 문제
해결 방법 :
- 단계의 마지막 부분에서, 백업 복사본의 작업을 생성함
- 먼저 완료되는 작업을 가져옴
- 이를 통해 작업 완료 시간을 크게 단축 시킴
Combiners

맵 태스크는 종종 동일한 키 (k)에 대해 ((k,v1), (k,v2), ... } 와 같은 형태의 많은 쌍을 생성합니다.
예를 들어, 단어 수 세기 예제에서 인기 있는 단어들이 이에 해당합니다.
네트워크 시간을 절약할 수 있는 방법 중 하나는 매퍼에서 값을 사전 집계(pre-aggregating)하는 것입니다:
- (combine(k, list(v1)) --> v2)
- Combiner는 보통 reduce 함수와 동일합니다.
이 방법은 reduce 함수가 교환 가능하고 결합 가능한 경우에만 작동합니다.
single mapper(단일 노드)의 모든 키 값을 결합합니다.
(훨씬 적은 양의 데이터를 복사하고 섞어서 작업 효율화 ! )
Partinin Function
- 키가 분할되는 방법을 제어할 수있는 기능
▪ 맵 작업에 대한 입력은 입력 파일의 연속 분할에 의해 생성됩니다
▪ 동일한 중간 키를 가진 레코드가 동일한 작업자에게 전달되도록 해야 하는 필요성 감소
시스템에서 기본 파티션 기능을 사용합니다:
- hash(키) mod R
해시 함수를 재정의하는 데 유용한 경우가 있습니다:
- 예를 들어 hash(hostname(URL)) mod R은 호스트의 URL이 동일한 출력 파일에 저장되도록 합니다.
MapReduce 처리의 예
MapReduce는 대규모 데이터 처리에 적합한 문제들을 해결하기 위해 설계된 프로그래밍 모델입니다.
다음은 MapReduce를 사용하여 해결할 수 있는 몇 가지 예시들입니다:
[1] 호스트 크기 문제:
대규모 웹 코퍼스에서, 각 호스트별로 전체 바이트 수(즉, 해당 호스트의 모든 URL에서 페이지 크기의 합)를 찾는 문제입니다. 메타데이터 파일에는 (URL, 크기, 날짜, ...) 형태의 줄이 있으며, 이를 분석하여 결과를 도출합니다.
[2] 링크 분석 및 그래프 처리:
웹 페이지의 링크 구조를 분석하거나 소셜 네트워크에서의 연결성 분석 등 그래프 기반의 데이터 처리에 MapReduce가 사용될 수 있습니다.
[3] 머신 러닝 알고리즘:
대규모 데이터셋에서 머신 러닝 모델을 훈련시키거나 예측을 수행하는 데 MapReduce가 활용될 수 있습니다.
예 ) 언어 모델: 통계 기반 기계 번역에서, 대규모 문서 코퍼스에서 모든 5-단어 시퀀스가 발생하는 횟수를 계산하는 문제입니다.
Map 단계에서는 문서에서 (5-단어 시퀀스, 카운트)를 추출하고, Reduce 단계에서는 이 카운트들을 결합합니다.
[4] Map-Reduce를 이용한 조인 연산:
두 파일에 저장된 R(A,B)과 S(B,C) 간의 자연 조인을 계산하는 문제입니다. 튜플은 (a,b) 또는 (b,c) 형태로 주어지며, MapReduce를 통해 이 두 데이터 세트를 조인할 수 있습니다.

이러한 예시들은 MapReduce가 분산 환경에서 대용량 데이터의 처리를 위한 강력한 도구임을 보여줌
각 단계에서 데이터를 효율적으로 분할하고 처리하여 복잡한 문제를 해결할 수 있음 !!!