Logistic Regression [ 비 선형 회귀 ]
Linear Regression은 연속형 변수 예를 들어, 주택 가격이나 온도와 같은 연속적인 값을 예측하는데 사용되었다면
Logistic Regression은 불연속적인 데이터 주로 이진 분류 문제에 사용된다.
이진 분류 문제 ? 주어진 입력 변수에 대해 두 개의 클래스 중 하나에 속할 확률을 예측하는 것을 목표로 한다.
예를 들어, 이메일이 스팸인지 아닌지를 예측하는 데 사용된다.
범주형 데이터와 선형 회귀
- 단순 선형 회귀의 예측 범위가 -inf ~ inf 에 반해 범주형 데이터인 경우 정답의 범위가 0과 1사이
- 0과 1사이를 벗어나는 예측은 예측의 정확도를 낮추게함
- 따라서 예측의 결과가 0과 1사이에 위치해야 함

Logistic Regression
Linear Regression 과 Logistic Function을 합쳐 정답이 범주형일 때 사용하는 Regression Model이다.

| Linear Regression | Logistic Function |
 |
 |
Threshold
Logistic Regression에서 Threshold(임계값)은 예측된 확률을 클래스로 할당하기 위한 기준값을 나타낸다.
이진 분류 문제에서는 모델이 계산한 확률이 특정 임계값을 넘으면 해당 예측을 Positive 클래스로 분류하고, 임계값을 넘지 못하면 Negative 클래스로 분류한다.
- 확률값을 범주형으로 변환할 때의 기준점으로 모델의 trade-offf를 조절하는 것이 가능하다. (ex) 확률이 0.5보다 크면 1, 그 외는 0
- Threshold를 높게 설정하면 모델이 Postive로 예측하는 기준을 높여 신회성이 향상된다. 하지만 False Postive가 증가할 수 있다.
- Threshold를 낮게 설정하면 민감도가 높아져 높은 True Postive 비율을 얻을 수 있지만 False Postive도 증가할 수 있다.
분류 모델의 성능 평가 지표
1. Confusion Matrix ( 오차 행렬 )
Training을 통한 Prediction의 성능을 측정하기 위해서 예측 value와 실제 value를 비교하기 위한 표이다.

True Postive Ratio ( TPR ) : True Postive / ( True Postive + False Negative )
> 예측을 P로 했는데 , 맞춘 확률
False Postive Ratio ( FPR ) : False Postive / ( False Postive + True Negative )
> 예측을 F로 했는데, 맞춘 확률
coufusion matrix 예시
| 예측값 | 정답 | |||||
| 1 | 1 | True Postive | ||||
| 1 | 1 | True Postive | Postive | Negative | ||
| 1 | 0 | False Postive | True | 2 | 2 | |
| 0 | 1 | False Negative | False | 1 | 1 | |
| 0 | 0 | True Negative | ||||
| 0 | 0 | True Negative | ||||
- TPR : 2/3 = 0.66
- FPR : 1/3 = 0.33
분류 문제의 Metric
1. Accuracy (정확도): Postive 와 Negative 가리지 않고 , 정확하게 맞춘 결과만 비교하는 지표

2. Precision (정밀도): 정밀도는 Positive로 예측한 샘플 중에서 실제로 Positive인 비율을 나타낸다.
예측한 Positive 중에서 실제로 Positive인 샘플의 비율을 측정한다. (높은 정밀도는 거짓 양성(FP)의 수가 낮다는 것을 의미)
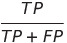
3. Recall (재현율 또는 민감도): 재현율은 실제로 Positive인 샘플 중에서 Positive로 예측한 비율을 나타낸다..
실제로 Positive인 샘플 중에서 얼마나 많은 비율을 감지했는지를 측정한다. (높은 재현율은 거짓 음성(FN)의 수가 낮다는 것을 의미)
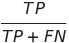
4. F1 Score: F1 Score는 정밀도와 재현율의 조화 평균으로, 두 지표 간의 균형을 나타내는데 사용되는 지표이다.
정밀도와 재현율이 균형을 이룰 때 높은 F1 Score를 얻을 수 있다.
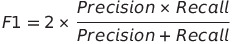
아래 내용은 metrix의 한계에 대해 잘 정리된 블로그 포스팅의 일부 내용입니다.
https://velog.io/@zxxzx1515/Confusion-matrix-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
Confusion Matrix 이해하기
Confusion Matrix는 Classification 문제에 있어서 가장 근간이 되는 Matrix다. 이 Confusion Matrix에 대해서 알아보자.
velog.io
3. 기존 metric의 한계점
- Threshold에 크게 영향을 받는다는 단점이 있다. 다시 예시를 가져오자.
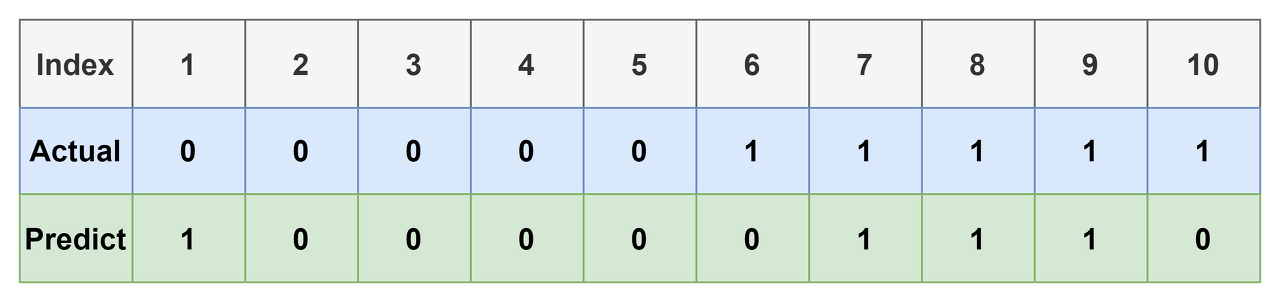
- 실제 우리의 모델은 0, 1로 Binary하게 예측하는 것이 아니다.
- Sigmoid등의 함수를 이용하여 아래 표와 같이 0~1 사이의 어떤 실수 값을 가지도록 하는 것이 일반적이다.
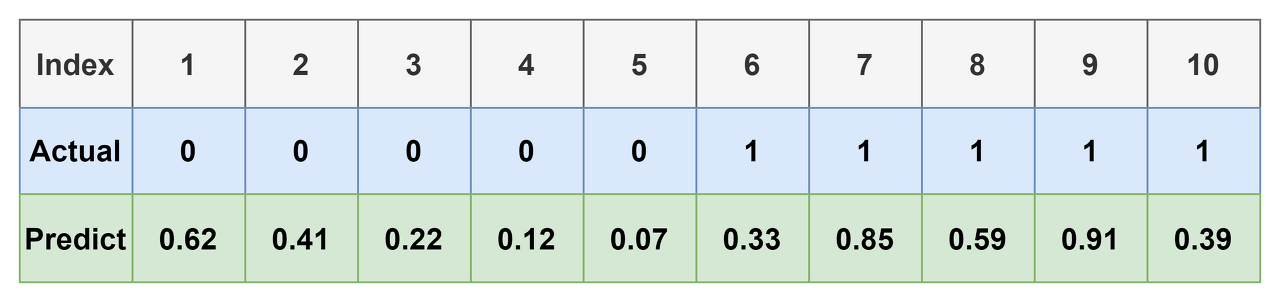
- 위 표에 0.5의 Threshold를 걸면 우리가 봤던 예시와 동일하다.
- 근데 0.6을 걸면? 0.7이면? Threshold에 따라 다른 결과가 도출 될 것이다.
- 예를 들어, threshold가 0.6인 경우에 대한 confusion matrix를 그려보자.
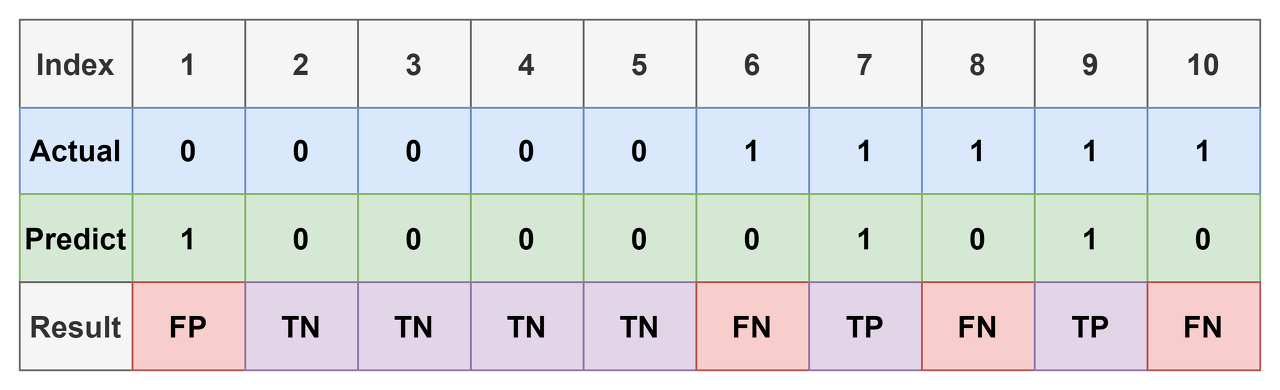
- 8번 index에 대해 결과가 바꼈고, 1개의 예측 결과가 TP에서 FN이 됐다.
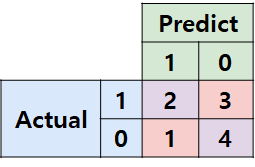
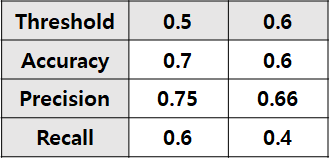
- 이에 따라 당연히 모델의 예측 결과도 아래처럼 바뀐다.
ROC (Receiver Operating Characteristic) Curve
- threshold에 대한 이진분류기의 성능을 한번에 표시한 지표로 사용된다.
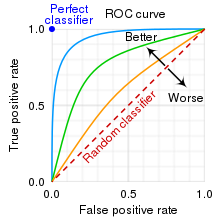
- 좌상단에 붙은 ROC 커브일수록 더 좋은 분류기를 의미한다.
- Y축은 True Postive로 예측 값이 T고 결과도 T인 경우를 의미한다.
- X축은False Postive로 예측 값이 T이지만, 결과는 F인 경우를 의미한다.
- curve의 휘어짐 정도는 두 개의 클래스를 잘 구별할 수 있는지에 대한 지표이다.
- curve위의 점은 threshold로 확률 공간 내 FPR과 TPR의 비율을 나타낸다.
- AUROC는 Curve의 밑면적을 나타낸다.
MultiClass인 경우의 분류
One or Nothing 방법으로 해결한다.
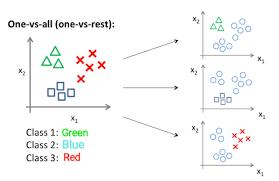
P( Y = G ) = 0.3, P( Y != G ) = 0.7
P( Y = B ) = 0.5, P( Y != B ) = 0.5
P( Y = R ) = 0.2, P( Y = R ) = 0.8
==> 확률이 제일 높은 Class를 에측 값으로 삼아서 Class를 선택한다
'Lab & Research > Artificial intelligence' 카테고리의 다른 글
| 머신러닝 알고리즘 - Boosting (0) | 2024.06.21 |
|---|---|
| 머신러닝 알고리즘 - Naive Bayes (0) | 2023.12.29 |
| 머신러닝 알고리즘 - Linear Regression (0) | 2023.12.17 |
| Genetic Alogorithm 의 주요 이슈 (0) | 2023.06.19 |
| Genetic Alogorithm 기초 (0) | 2023.05.21 |



