진화 연산이란 ?
진화 연산(Evolutionary Computation)은 자연의 진화 원리를 모방하여 문제 해결을 위한 최적화 알고리즘을 개발하는 컴퓨터 과학 분야입니다.
이 분야는 유전 알고리즘, 진화 전략, 유전적 프로그래밍 등 다양한 하위 분야로 나뉘며, 모두 최적화 문제 해결을 위한 다양한 알고리즘 기법을 제공합니다.
이러한 기술은 다양한 분야에서 사용되는데 예를 들어, 제조 공정 최적화, 로봇 제어, 금융, 게임 개발, 그리고 기계 학습 등에서 활용됩니다. 진화 연산은 전체 탐색을 수행하거나 최적해를 찾는데 있어서 높은 성능과 유연성을 제공하여, 많은 실제 문제에서 적용되고 있습니다.
생물학적 진화와 진화 연산이 다루는 용어의 비교
| 진화 연산이 다루는 문제 | 생물학적 진화 과정 |
| 문제 공간 | 환경 |
| 해결책 | (개별) 염색체 |
| 변수 | 유전자 |
| 퀄리티 | 적합도 ( Phenotype : 표현형 > 유전 조합에 의해 나타나는 개체의 모든 외부적 특성) |
Genotype vs Phenotype
유전 알고리즘에서 genotype(유전자 형질)과 phenotype(표현형)은 각각 해를 표현하는 방식과 그 해의 실제 특성을 의미합니다.

genotype은 유전자 조합의 형태로, 각각의 개체에 해당하는 염색체(chromosome)가 표현합니다.
이러한 genotype은 binary string, real number, permutation 등의 형태로 표현될 수 있습니다.
유전 알고리즘에서는 이 genotype을 변이(mutate)시키고, 교배(crossover)하여 새로운 genotype을 생성합니다.
phenotype은 genotype으로부터 유도된 개체의 실제 특성을 의미합니다.
유전자 조합의 변화는 phenotype의 변화를 유발하며, phenotype은 문제 해결을 위한 목적 함수(objective function)에 따라 평가됩니다.
예를 들어, 유전 알고리즘이 최적화 문제를 해결하는 경우, phenotype은 목적 함수에 의해 측정된 해의 품질(quality)입니다.
따라서, 유전 알고리즘은 초기 해의 genotype을 생성하고, 이를 변이 및 교배하여 새로운 genotype을 생성하며, phenotype을 평가하여 새로운 해를 발견하는 방식으로 최적화 문제를 해결합니다. 이러한 과정을 반복하여 최적해를 탐색하는데, phenotype이 문제 해결의 성공 여부를 판단하는 중요한 역할을 합니다.
– Genotype → Phenotype (o)
– Genotype ↚ Phenotype (x)
진화연산에서 자연선택의 역할
진화연산에서 자연선택은 중요한 개념 중 하나입니다. 다음은 자연선택에 대한 설명입니다.
[1] 종의 기원:
"유리한 변이를 보존하고 불리한 변이를 거부함"
[2] 생존을 위한 경쟁:
생존 가능한 개체의 수보다 더 많은 개체가 탄생하므로 지속적인 생존을 위한 경쟁이 있습니다.
[3] 이점을 가진 개체의 생존:
어떤 이점을 가진 개체는 생존할 가능성이 더 높습니다. (survival of the fittest)
[4] 자연선택에서 중요한 측면:
- 환경에 대한 적응
- 상호 교배할 수 없도록 서로 다른 집단으로 분리
[5] 유전자의 변이:
개체의 유전자에 작은 변화가 일어나면, 특히 작은 규모의 인구에서는 유전적 변동이 쉽게 발생할 수 있습니다. 이것을 유전적 드리프트 (genetic drift) 라고 부릅니다.
[6] 적합도 평가 :
수학적으로 표현되는 표현은 적합도(fitness)입니다. ==> (생존에 대한 성공 확률 척도 )
자연선택은 생물의 생존과 진화에 중요한 역할을 합니다. 이를 통해 생물은 환경에 대한 적응력을 획득하고, 이에 따라 적응력이 높은 개체들이 생존하게 됩니다. 이렇게 생존한 개체들은 그 다음 세대에 더 많은 후손을 낳으며, 이 과정을 반복하면서 진화가 발생합니다.
따라서, 진화연산에서는 이러한 자연선택의 원리를 모방하여 다양한 종류의 알고리즘을 개발하게 됩니다. 이를 통해 최적의 해결책을 찾아내거나, 다양한 문제를 해결할 수 있습니다.
진화 연산의 기초
유전 알고리즘에서는 크게 다섯 가지의 단계가 고려됩니다.
이 다섯 단계를 통해 부모의 특성을 전달받으면서, 다음 세대에 자손을 진화시키고 마지막으로 생존 가능성이 가장 높은 적합한 세대와 유전자들을 찾을 수 있습니다.
- 초기 모집단 생성
- 판별 함수 ( 적합도 함수 ) 생성
- 선택 과정
- 크로스 오버
- 돌연변이
유전자 알고리즘(Genetic Algorithm)에서는 문제 해결을 위한 솔루션을 individual 로 표현합니다.
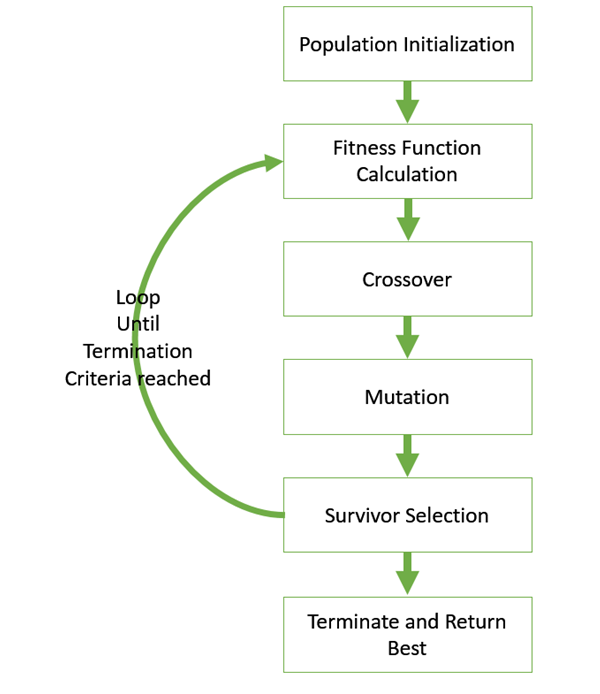
초기 모집단 생성에서는 각 개인은 일련의 매개 변수(유전자)로 특징지어지며, 이 유전자들은 문자열로 연결되어 염색체(솔루션)를 형성합니다. 이진 값(1과 0)으로 표현하는 것이 일반적이다 ( ex> 10111011... ) , 이떄 각 염색체는 문제 해결을 위한 하나의 해로 표현 가능하다.
적합도 함수란 각 염색체의 적합도 함수 기능은 각 individual이 얼마나 적합한지를 결정합니다.
이것은 각 염색체 적합도 점수(fitness score)를 제공하며, 번식을 위해 선택될 확률은 적합도 점수를 기반으로 합니다.
선택 단계에서는 가장 적합한 개체를 선택하여 다음 세대에 유전자를 전달합니다. 두 부모 유전자는 적합도 점수에 따라 선택되며, 점수가 높은 유전자는 번식을 위해 선택될 기회가 더 많습니다.
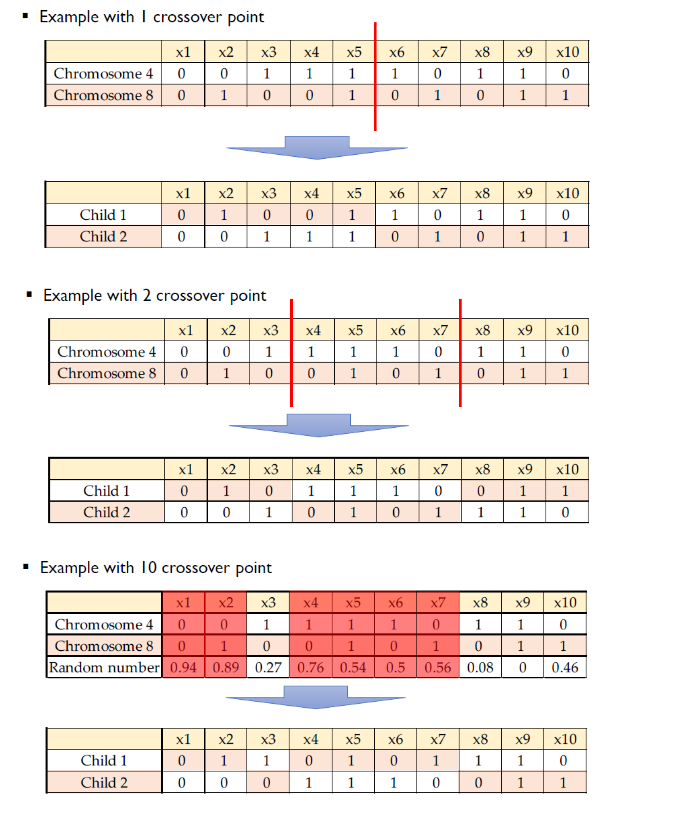
크로스 오버 단계의 교차는 유전자 알고리즘에서 가장 중요한 단계입니다. 교배할 각 부모 유전자 쌍에 대해 교차점은 유전자 내에서 무작위 로 선택됩니다. 자손은 교차점에 도달할 때까지 부모의 유전자를 서로 교환하여 생성됩니다.
돌연변이 단계에서는 어떤 새로운 자손이 형성되면 그들의 유전자 중 일부는 낮은 확률로 돌연변이를 일으킬 수 있습니다. 이는 모집단 내의 다양성을 유지하고 조기 수렴을 방지하기 위해 발생합니다.
크로스 오버 단계와 돌연변이 단계를 통해서 새롭게 생성된 자손 개체를 offspring이라고 한다. 이는 모집단 내에서 다양성을 유지하고 적합성이 높은 개체를 선택하여 모집단을 개선하는 데 기여합니다.
새로운 offspring을 대체하고하면서 세대를 진화시키고 모집단이 수렴하면 알고리즘이 종료됩니다. 다시 말해 이전 세대와 크게 다른 자손을 생산하지 않을 때 종료되며, 이는 문제에 대한 일련의 솔루션을 제공했다고 가정한다.
아래는 이를 기반으로 한 간단한 유전 알고리즘을 파이썬 코드로 구현한 것이다.
Python GA example Code
# Generate n initial chromosomes(solutions)
population = generate_initial_population(n)
# Repeat until stop condition is satisfied
while not stop_condition_satisfied:
# Reproduce some best solutions (elitism)
elites = select_elites(population)
# Initialize offspring list
offspring = []
# Generate k offspring
for i in range(k):
# Select two parent chromosomes
p1, p2 = select_parents(population)
# Generate offspring through crossover
child = crossover(p1, p2)
# Mutate offspring
child = mutate(child)
# Add offspring to list
offspring.append(child)
# Replace k chromosomes in population with offspring
population = replace_population(population, elites, offspring)
# Return the best chromosome in population
best_solution = get_best_solution(population)
[1] 유전 알고리즘의 파라미터
Generation gap (k/n)
- k ≈ n : generational GA
이 값이 population size(n)와 같은 경우를 "generational GA"라고 하며, 각 세대에서 모든 유전자들이 완전히 새로운 자손으로 대체됩니다.
- k ≈ 1 : steady-state GA
반면, k 값이 1에 가까울수록 "steady-state GA"가 되며, 각 세대에서 하나의 자손만 생성하고, 가장 적합한 부모 유전자 중 하나와 대체됩니다.
[2] 유전 알고리즘의 종료 조건
Generation gap (k/n)
− fixed number of iterations
− probability of population convergence
이는 GA가 실행되는 동안 종료되는 시점을 나타냅니다. 종료 조건에는 다양한 종류가 있지만, 가장 일반적인 두 가지 종료 조건은 고정된 반복 횟수와 전체 인구의 수렴 확률입니다.
종료 조건을 만족하면, 최적의 해결책을 찾았거나 더 이상 개선할 수 없는 상태이므로 GA가 종료됩니다.
GA를 활용하여 해결할 수 있는 2가지 예제
• K-way Graph Partition Problem (GPP)
Traveling Salesman Problem (TSP)은 여러 도시들이 존재하고, 각 도시를 한 번씩 방문하고 다시 시작점으로 돌아오기 위한 최단 경로를 찾는 문제입니다.
이는 여러 분야에서 중요한 문제로 다양한 응용 분야에서 활용되고 있습니다.
TSP는 NP-완전 문제로, 도시의 개수가 적을 때는 브루트포스 알고리즘을 이용해 모든 경우의 수를 탐색하여 최단 경로를 찾을 수 있습니다.
그러나 도시의 개수가 증가함에 따라 탐색해야 할 경우의 수가 기하급수적으로 증가하기 때문에, 현재는 정확한 최적해를 구하기 어려운 문제로 여겨지고 있습니다. 따라서 이를 근사하는 다양한 알고리즘들이 제안되어 왔습니다.
• Traveling Salesman Problem (TSP)
K-way Graph Partition Problem (GPP)은 그래프를 K개의 부분 그래프로 분할하는 문제입니다.
이 문제는 NP-완전 문제로 알려져 있으며, 그래프 이론에서의 다양한 응용 분야에서 사용됩니다.
예를 들어, 회로 설계, 이미지 분할, 분산 시스템의 자원 할당, 그리드 컴퓨팅 등에 사용될 수 있습니다.
GPP의 목적은 각 부분 그래프의 크기를 균등하게 만드는 것입니다. 그러나 이 문제는 최적해를 찾기 어려우며, 근사해를 구하는 것이 일반적입니다. 따라서 진화 연산을 사용하여 이 문제를 해결할 수 있습니다.
+
CrossOver
Mutation
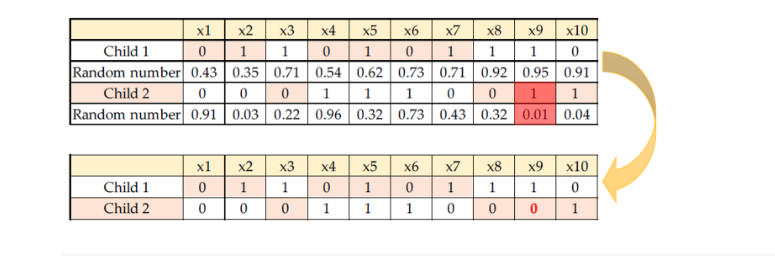
유전 알고리즘의 핵심 기법인 변이(mutation)은 현재 해와 비슷한 해를 찾기 위해 휴리스틱 탐색을 하는 과정에서 일어난다.
각 염색체가 가진 정보의 작은 부분을 무작위로 변경하여 새로운 해를 만들어내는 것이다.
이 과정에서 일어나는 정보의 변환은 유전 과정에서의 돌연변이와 유사한 현상이고, 이를 통해 검색 공간을 더욱 다양화시키고 전역 최적해를 찾을 확률을 높인다.
변이는 교배(crossover)와 함께 다음 세대에 대한 개체 생성 방식 중 하나이며, 이전 세대에서 선택한 염색체를 상속으로 받아 변형시킨 후 새로운 해를 생성한다. 변이는 모든 부분(유전자)에 대해 적용될 수 있지만, 보통 하나 또는 일부 소수의 유전자만을 변경한다.
결과적으로 변이는 다양한 차원에서 검색 공간을 확장하며, 다수의 해를 만들어내어 전역 최적해를 찾는데 기여한다. 변이 확률(rate)이 높을수록 다양성이 증가하여 근사치의 해를 탐색하기에 용이하지만, 탐색속도가 느려질 수 있다. 따라서 일반적으로 변이 확률은 낮지만 적절한 값으로 설정하는 것이 중요하다.
'Lab & Research > Artificial intelligence' 카테고리의 다른 글
| 머신러닝 알고리즘 - Naive Bayes (0) | 2023.12.29 |
|---|---|
| 머신러닝 알고리즘 - Logistic Regression (0) | 2023.12.18 |
| 머신러닝 알고리즘 - Linear Regression (0) | 2023.12.17 |
| Genetic Alogorithm 의 주요 이슈 (0) | 2023.06.19 |
| Genetic Alogorithm 기초 (0) | 2023.05.21 |



